Abstract
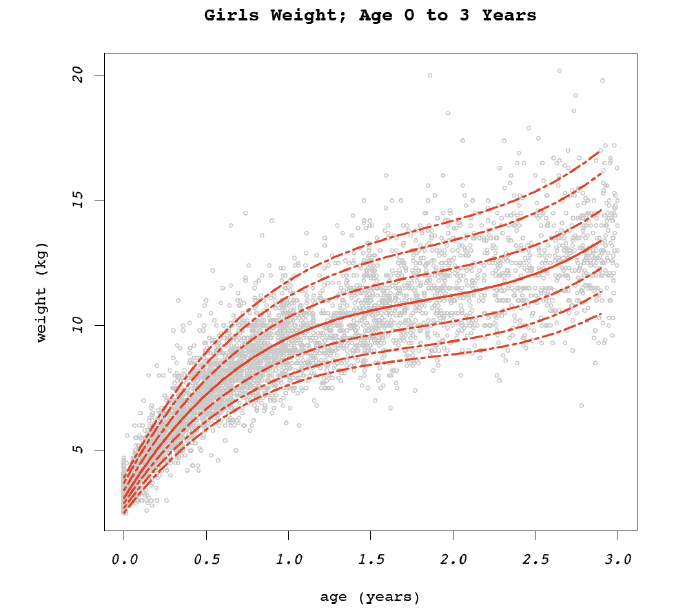
Assessing the accuracy of the $\tau^{th}$ ($\tau\in [0,1]$) quantile parametric regression function estimate (see Koenker and Bassett 1978) requires valid and reliable procedures for estimating the asymptotic variance-covariance matrix of the estimated parameters. This covariance matrix depends on the reciprocal of the density function of the error (sparsity function) evaluated at the quantile of interest which, particularly for heteroscedastic non-iid cases, results in a complex and difficult estimation problem. It is well-known that the construction of confidence intervals based on the quantile regression estimator can be simplified by using a bootstrap. To construct confidence intervals in quantile regression we propose an effective and easy to apply bootstrap method based on the idea of Silverman’s (1986) kernel smoothing approach. This proposed bootstrapping method requires the estimation of the conditional variance function of the fitted quantile. After fitting the $\tau^{th}$ quantile function, we obtain the residuals, which are squared and centered to zero. Estimating the conditional mean function of the centered squared residuals gives the conditional variance function of the errors about the estimated $\tau^{th}$ quantile. Using an estimate of the conditional variance function allows the standardisation of the residuals which are then used in Silverman’s (1986) kernel smoothing bootstrapping procedure to make inferences about the parameters of the $\tau^{th}$ quantile function. In this talk we will discuss a variety of approaches to estimate the conditional variance function. These will include the adaptation of GLMs as well as non-parametric regression based estimation. These different approaches have been assessed under various data structures simulated in R and compared to several existing methods computable in the quantreg package contributed by Roger Koenker. The simulation studies show good results in terms of coverage probability and the spread of the constructed parameters confidence intervals when compared with existing methods. This methodology is also applicable to a wider class of regression models with heteroscedastic errors where the transformation to normality is difficult to achieve or maybe undesirable given a need to preserve the original data scale.
Tatjana Kecojevic
statistician and ever evolving data scientist
My research work has developed my knowledge and skills within the area of applied statistical modelling. As such, the area of my research enhances the opportunities for cross discipline projects.